本文是本文的一部分TechXchange:RISC V
你将学习:
- RISC-V作为GPU的工作原理。
- 使用RISC-V设计GPU涉及哪些问题?
任何研究过GPU架构的人都知道它是矢量处理器的SIMD构造。它是一种超高效的并行处理器,从运行模拟和精彩的游戏到教机器人如何获取人工智能,以及帮助聪明人操纵股票市场,它被用于各种领域。它甚至在我写这个的时候检查我的语法。
但GPU领域一直是一个专有领域,其内部工作是AMD、英特尔、英伟达和其他一些开发商的IP和秘方。如果有一组新的为3D图形和媒体处理设计的图形指令呢?嗯,可能有。
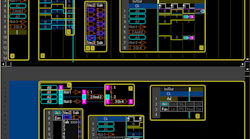
新的指令正在RISC-V基向量指令集上构建。在核心RISC-V ISA的精神下,他们将添加对特定于图形的新数据类型的支持,作为分层扩展。支持向量、先验数学、像素和纹理以及Z/Frame缓冲区操作。它可以是一个融合的CPU-GPU ISA。Pixilica叫它RV64X(图1),因为指令将是64位长(32位不足以支持健壮的ISA)。
该组织表示,他们的动机和目标是希望创建一个具有自定义可编程性和可扩展性的小型、区域高效的设计。它应该提供低成本的知识产权所有权和开发,而不是与商业产品竞争。它可以在FPGA和ASIC目标中实现,并且将是免费和开源的。最初的设计,针对低功耗微控制器,将兼容Khronos Vulkan,并支持其他api (OpenGL, DirectX等)。
GPU + RISC-V
目标硬件将有一个GPU功能单元加上一个RISC-V核心。该组合显示为带有编码为标量指令的64位长指令的处理器。诀窍是编译器将从带前缀的标量操作码生成SIMD指令。在其他特性中,有一个变量问题,即预测SIMD后端;分支跟踪;精确的异常;和矢量前端。设计将包括16位定点版本和32位浮点版本。前者适用于FPGA实现。
“不需要任何RPC/IPC调用机制将3D API调用发送到或从未使用的CPU内存空间到GPU内存空间,反之亦然,”团队说。
“融合”的CPU-GPU ISA方法的优点是可以在微码中使用标准的图形管道,以及支持自定义着色器的能力。甚至射线追踪扩展也可以包括在内。
设计将采用Vblock格式(来自Libre GPU的努力):
- 它有点像VLIW(只是不是真的)。
- 指令块以寄存器标记为前缀,这些标记为该指令块中的标量指令提供额外的上下文。
- 子块包括向量长度,混合,向量/宽度覆盖,和预测。
- 所有这些都被添加到标量操作码中!
- 没有向量操作码(也不需要任何)。
- 在向量上下文中,它是这样的:如果标量操作码使用寄存器,并且该寄存器在向量上下文中列出,则激活向量模式。
- 激活导致硬件级for循环发出多个连续的标量操作(而不仅仅是一个)。
- 实现者可以自由地以任何他们想要的方式实现循环——simd、多问题、单执行;几乎任何东西。
RV32-V向量处理2到4个元素/8、16或32位/元素向量操作。也将有专门的说明,通用3D图形渲染管道64位和128位固定和浮点XYZW点;8-, 16-, 24-和32位RGBA像素;8- 16位每组件UVW texels;以及灯光和材质设置(Ia, ka, Id, kd, Is, ks…)。
属性向量用4 × 4矩阵表示。该系统将支持2 × 2和3 × 3矩阵。矢量支持可能也适用于使用人工智能和机器学习应用中常见的8位整数数据类型的数值模拟。
定制光栅,如样条、SubDiv曲面和补丁,可以包含在设计中。该方法还允许包含自定义管道阶段、自定义几何/像素/帧缓冲阶段、自定义网格化器和自定义实例化操作。
RV64X
RV64X参考实现包括:
- 指令/数据SRAM缓存(32kb)
- 微码SRAM (8 kB)
- 双功能指令解码器(硬连线实现RV32V和X;用于自定义ISA的微编码指令解码器
- 四矢量ALU(32位/固定ALU /浮动ALU)
- 136位寄存器文件(1k个元素)
- 特殊功能单元
- 纹理单元
- 可配置的本地帧缓冲区
RV64X是一个可扩展的架构(图2).它的融合方法是新的,就像使用可配置寄存器来定制数据类型一样。用户定义的、基于sram的微代码可以用于实现扩展,如自定义光栅化工作台、射线跟踪、机器视觉和机器学习。一个单一的设计可以应用到一个独立的图形微控制器或一个具有可扩展着色器单元的多核解决方案。
对于RISC-V的图形扩展可以解决可伸缩性和多语言问题。这可以实现更高层次的用例,导致更多的创新。
接下来是什么
RV64X规范仍处于早期开发阶段,可能会发生变化。正在建立一个讨论论坛。直接的目标是用指令集模拟器构建一个示例实现。这将运行在使用开源IP加上作为开源项目设计的自定义IP的FPGA实现上。联系作者Atif Zafar:Atif@Pixilica.com如果你想参与更多的话。